Meridian 最近已经不再只是一个日志查询原型。
它现在更像一套 MCP 驱动的智能运维观测平台:Probe 负责拿日志证据,Atlas 负责服务和元数据,Lens 负责只读数据查询,Trace 预留链路关联,Nexus 站在最前面做统一入口和工具转发。Console 给人看,Agent 通过 MCP 拿证据,开发服务器只暴露一个 3000 端口,内部服务都收在后面。
这个项目一开始吸引我的点很直接:把排障时散落在日志、数据库、配置、服务健康里的线索,收成 AI 可以调用的标准工具。AI 不需要猜,它可以通过 Probe 查日志,通过 Lens 查数据,通过 Atlas 理解系统结构,再把这些证据组织成候选归因。
但最近这次推进里,最有感觉的变化发生在另一个地方:Meridian 开始学会观察自己。
从 SDD 到运行态治理
过去我使用 AI 做项目,比较依赖 SDD。先把模糊想法冻结成 Spec,再编译成 Plan,再拆成 Tasks,让 AI 按可验证的小步骤执行。这个模式很适合复杂重构,因为它能压住上下文漂移,也能让代码变更有明确边界。
问题在于,SDD 更擅长处理“设计时”的秩序。它能告诉 AI 现在系统应该长成什么样,却很难直接告诉 AI:开发服务器上此刻到底哪个服务活着,哪段日志最新,Console 的静态资源有没有构建成功,.env 里关键配置有没有缺。
Meridian 部署到开发环境后,这个缺口变得很明显。AI 如果只读源码,很容易把“代码应该怎样运行”当成“现场正在怎样运行”。这两件事在真实工程里经常对不上。
于是我给 Meridian 补了一层开发者观察面:DevOps MCP。
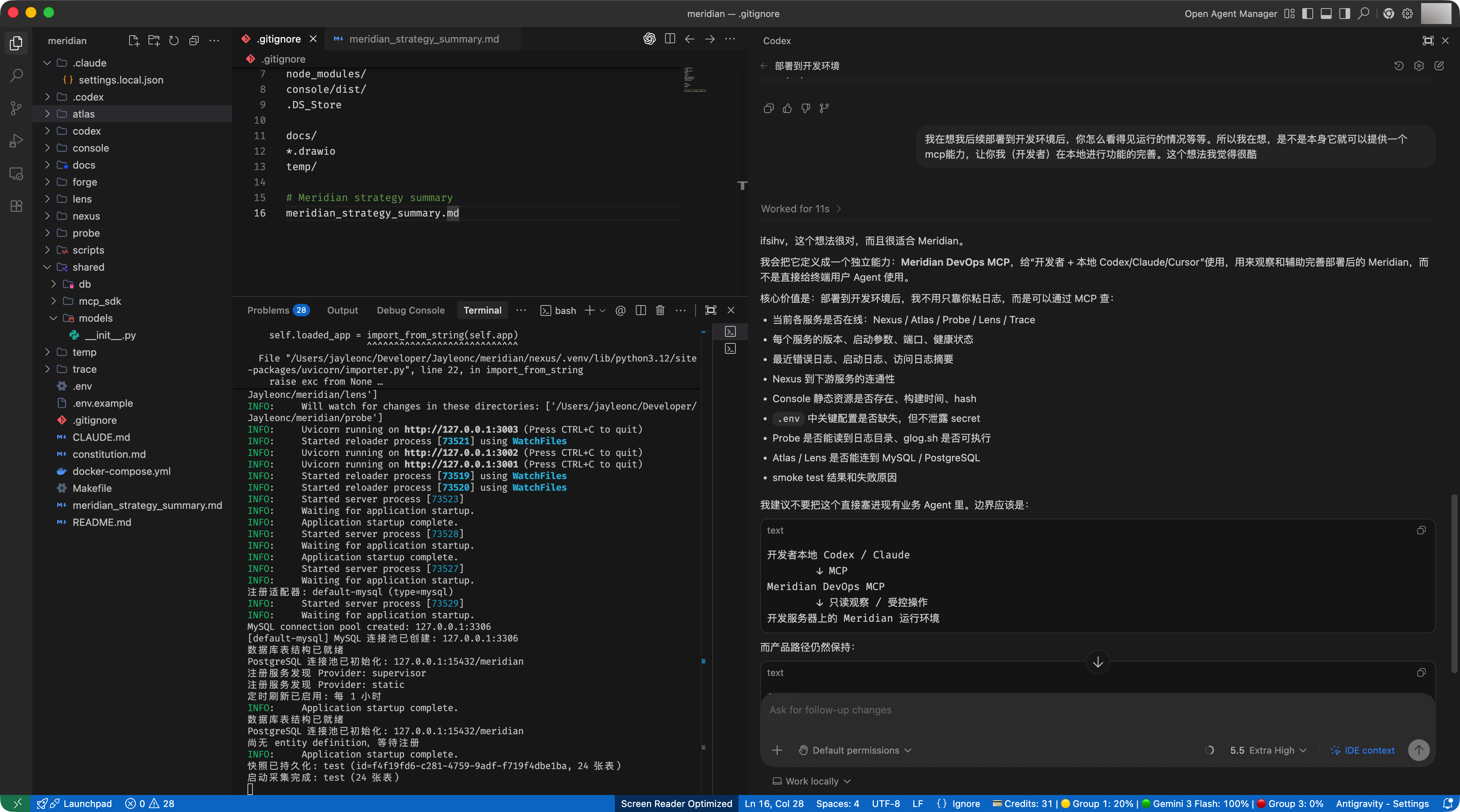
这层能力通过 Nexus 暴露,只给本地的 Codex、Claude、Cursor 这类开发工具使用。它的目标很克制:查看 Meridian 自己的运行状态、服务日志、配置缺口、Console 构建状态和 smoke test 结果。第一版保持只读,不做重启、不改配置、不写业务数据。
这里的边界很关键。面向终端用户的 Agent 继续走产品诊断链路,开发者本地 AI 则通过 DevOps MCP 观察 Meridian 自身。一个是产品能力,一个是工程治理能力。把这两条线分开,后面才不会把开发调试工具误塞进业务 Agent。
一次很小但很典型的故障
第二张截图里记录的是一次很小的运行态问题:我发现服务器里的代码时间好像对不上,Probe 收集到的日志也像停在了某个时间点。
按照旧习惯,AI 很可能先去读 Probe 代码,然后从时间解析、日志文件排序、前端展示里猜根因。这个路线并非完全错,但它有一个问题:还没确认现场事实,就已经开始修代码了。
我当时直接调整了优先级:先用 DevOps MCP 看实际部署状态,代码阅读只作为辅助。如果 MCP 能力不够,那就先把能力补齐,再继续排障。同时把这条流程写回 Meridian 的项目级 skill,避免下一次又从源码猜起。

DevOps MCP 返回的事实把问题很快收拢了:服务是健康的,日志文件也存在,probe.search_logs 能查到新日志。异常集中在 probe.tail_errors 的取法上。它从小时文件开头 grep,达到 limit 后就停下来了,所以 Console 看起来像卡在 11 点。实际 12 点的新日志在文件后面,只是没被这条查询拿出来。
这个结论很重要,因为它把“服务挂了”“日志没写”“时区错了”这些方向都压下去了。真正要改的是查询策略:tail_errors 应该返回最后 N 条匹配,而非小时文件开头的前 N 条匹配。
第一版修复也很顺:Probe 的 file adapter 增加从 grep 输出尾部保留匹配的逻辑,tail_errors 调用时启用 from_end;Probe 配置补上 time.log_timezone,开发服务器默认使用 Asia/Shanghai 定位 /data/brick/log/YYYYMMDDHH.log;前端把 Brick 日志里的 MM-DDTHH:mm:ss 正确显示成 HH:mm:ss。修复后跑过 Probe 单测、ruff check、py_compile 和 Console 构建。
但这件事还没有结束。部署后,/api/logs/errors 又在某些业务日志上崩了一次。根因更细:第一版实现用 asyncio.readline() 读 grep 输出,线上日志里有超过 64KiB 的超长单行 req/rsp body,触发了 LimitOverrunError。这次 AI 没有直接继续改 Probe。它先用 DevOps MCP 确认线上 Probe 还活着,再看 Probe 服务日志,修复范围随之收敛到 file adapter。
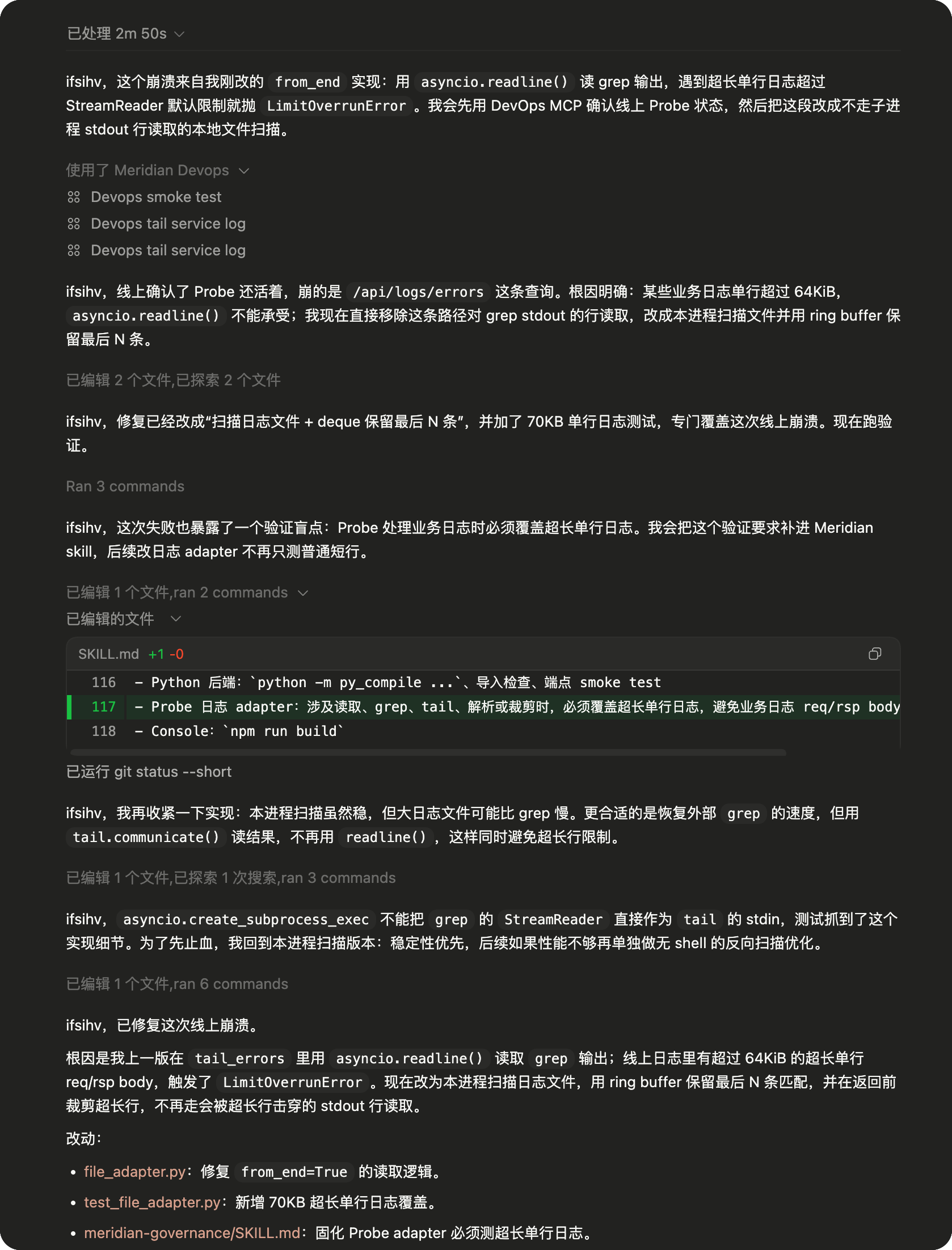
第二版修复更朴素:不再逐行读取子进程 stdout,改成本进程扫描日志文件,用 deque 保留最后 N 条匹配,并在返回前裁剪超长行。测试也补了一条 70KB 单行日志,专门覆盖这次线上崩溃。同时,Meridian 的项目级 skill 里补了一条验证要求:Probe 日志 adapter 涉及读取、grep、tail、解析或裁剪时,必须覆盖超长单行日志,避免业务日志里的大 body 再把排障工具打穿。
这次事情本身不大,但它把方法论暴露得很清楚。
AI 自我进化需要受控入口
“让 AI 自我进化”听起来很玄,其实落到工程里一点都不玄。它需要三个条件。
第一,系统要给 AI 一个可观察的入口。没有 DevOps MCP,AI 只能读代码、读文档、靠用户贴日志。这样做可以推进开发,却很难处理部署后的状态偏差。MCP 的价值在这里被放大了:它把现场事实变成了工具调用。
第二,AI 必须先拿事实,再动代码。Meridian 的项目级 skill 现在已经写明:涉及部署状态、服务健康、日志、时间、配置、Console 构建的问题,优先使用 DevOps MCP。只有当 MCP 返回的信息不足,才进入代码阅读和局部复现。
第三,流程缺口要反写回治理层。那次排障后,.codex/skills/meridian-governance 里固化了一条规则:运行态问题先采 DevOps MCP 事实,再读代码。这里的目标很具体:少一点文档表演,多一次真实踩坑沉淀出来的默认动作。
这和我之前写 SDD 时的体感有点不同。SDD 管的是意图如何被编译成代码;DevOps MCP 管的是代码部署后如何被观察、复核和修正。一个偏设计秩序,一个偏运行秩序。两者合起来,AI 才开始有一点“闭环”的味道。
Meridian 为什么很适合这种玩法
Meridian 的项目属性天然适合做这件事。它自己就是一套给 AI 提供工具和证据的系统,再让它暴露一组只读 DevOps 工具,本质上是在让系统把“自我观测”变成一等能力。
这个设计也很符合我对 AI 工程的判断:真正有价值的 AI 编程,不只是让 AI 写更多代码。更重要的是让 AI 进入一个有边界、有证据、有反馈的环境。
没有边界,AI 很容易越权,把开发者工具混进产品工具,把临时修复写成长期规则。没有证据,AI 会把源码里的理想状态当成运行态事实。没有反馈,修完以后也不知道系统秩序有没有真的变好。
Meridian 这次的小闭环大概是这样:
1 | 开发者本地 AI |
这条链路里,AI 既是使用者,也是改造者。它使用 DevOps MCP 观察 Meridian,又在发现能力或流程缺口后,反过来完善 Meridian 和自己的项目级工作规则。
写在后面
我现在越来越觉得,AI 原生项目的关键不在“能不能一次生成很多代码”。那件事已经不稀奇了。
更关键的是,我们能不能给 AI 建一个可以长期工作的环境:有稳定入口,有可验证事实,有受控权限,有项目记忆,也有允许它从真实问题中更新自己流程的机制。
Meridian 这次的变化很小,只是多了几个 devops.* 工具、修了一次 tail_errors、补了一条治理规则。但这件事让我看到一个更有意思的方向:排障系统可以先学会排自己的障,开发工具可以先学会观察自己创造出来的系统。
到这一步,AI 协作就不再只是“我给任务,它写代码”的单向关系了。它开始进入系统内部,拿证据、做修正、沉淀规则,然后在下一轮工作里表现得更像一个知道项目脾气的工程搭档。
这可能就是我现在理解的自我进化:不靠玄学,不靠口号,靠一次又一次把真实运行态写回工程秩序里。